ConOffense: Multi-modal multitask Contrastive learning for offensive content identification
Abstract
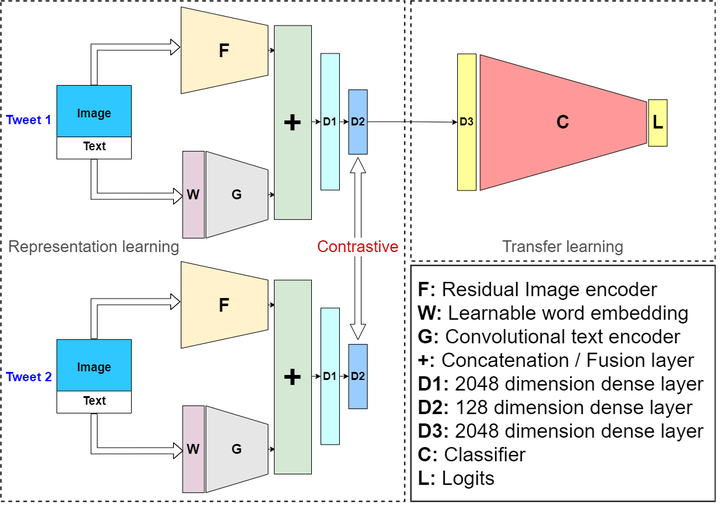
Hateful or offensive content has been increasingly common on social media platforms in recent years, and the problem is now widespread. There is a pressing need for effective automatic solutions for detecting such content, especially due to the gigantic size of social media data. Although significant progress has been made in the automated identification of offensive content, most of the focus has been on only using textual information. It can be easily noticed that with the rise in visual information shared on these platforms, it is quite common to have hateful content on images rather than in the associated text. Due to this, present day unimodal text-based methods won’t be able to cope up with the multimodal hateful content. In this paper, we propose a novel multimodal neural network powered by contrastive learning for identifying offensive posts on social media utilizing both visual and textual information. We design the text and visual encoders with a lightweight architecture to make the solution efficient for real world use. Evaluation on the MMHS150K dataset shows state-of-the-art performance of 82.6 percent test accuracy, making an improvement of approximately +14.1 percent accuracy over the previous best performing benchmark model on the dataset.
Debaditya Shome
Graduate researcher experienced in AI / ML
My research interests include Self-supervised learning, Generative learning, Computer Vision and it’s interplay with different modalities of data such as natural language and audio.