COVID-Transformer: Interpretable COVID-19 Detection using Vision Transformer for Healthcare
Abstract
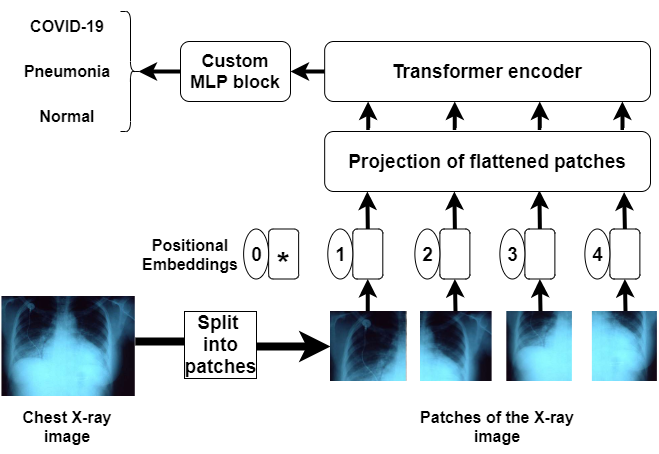
In the recent pandemic, accurate and rapid testing of patients remained a critical task in the diagnosis and control of COVID-19 disease spread in the healthcare industry. Because of the sudden increase in cases, most countries have faced scarcity and a low rate of testing. Chest x-rays have been shown in the literature to be a potential source of testing for COVID-19 patients, but manually checking x-ray reports is time-consuming and error-prone. Considering these limitations and the advancements in data science, we proposed a Vision Transformer based deep learning pipeline for COVID-19 detection from chest x-ray based imaging. Due to the lack of large data sets, we collected data from three open-source data sets of chest x-ray images and aggregated them to form a 30K image data set, which is the largest publicly available collection of chest x-ray images in this domain to our knowledge. Our proposed transformer model effectively differentiates COVID-19 from normal chest x-rays with an accuracy of 98 % along with an AUC score of 99 % in the binary classification task. It distinguishes COVID-19, normal, and pneumonia patient’s x-rays with an accuracy of 92 % and AUC score of 98 % in the Multi-class classification task. For evaluation on our data set, we fine-tuned some of the widely used models in literature namely EfficientNetB0, InceptionV3, Resnet50, MobileNetV3, Xception, and DenseNet-121 as baselines. Our proposed transformer model outperformed them in terms of all metrics. In addition, a Grad-CAM based visualization is created which makes our approach interpretable by radiologists and can be used to monitor the progression of the disease in the affected lungs, assisting healthcare.
Debaditya Shome
Graduate researcher experienced in AI / ML
My research interests include Self-supervised learning, Generative learning, Computer Vision and it’s interplay with different modalities of data such as natural language and audio.